Context Engineers para Product Managers
Contexto é o ativo mais subestimado de qualquer aplicação com IA generativa. O modelo é commodity cada vez mais barata. O que diferencia é como você orquestra instruções, exemplos, conhecimento, memória e ferramentas para entregar resultado confiável no menor custo. Se sua equipe ainda discute “qual modelo usar” antes de decidir “qual contexto fornecer”, você está priorizando a variável errada.
Por que isso importa agora
As janelas de contexto cresceram para centenas de milhares de tokens e já existem ofertas com milhões. Isso não significa jogar tudo lá dentro. Significa que você pode compor respostas a partir de múltiplas fontes, com governança. O efeito prático é simples. Produtos que dominam a engenharia de contexto reduzem alucinação, aumentam acurácia percebida e destravam novos fluxos de trabalho com agentes e ferramentas. Produtos que ignoram isso viram demo bonita que quebra na primeira semana.
Esse aqui te prepara de verdade: Construa uma carreira à prova do futuro, liderando produtos mais inteligentes e eficientes com IA. Acesse aqui. Cupom de 10%: PRODUCTGURUS
O mapa do contexto em seis blocos
Use o diagrama como referência e trate cada bloco como um “tipo de evidência” que você entrega ao modelo. O trabalho do PM é decidir a ordem, o peso e o orçamento de cada evidência.
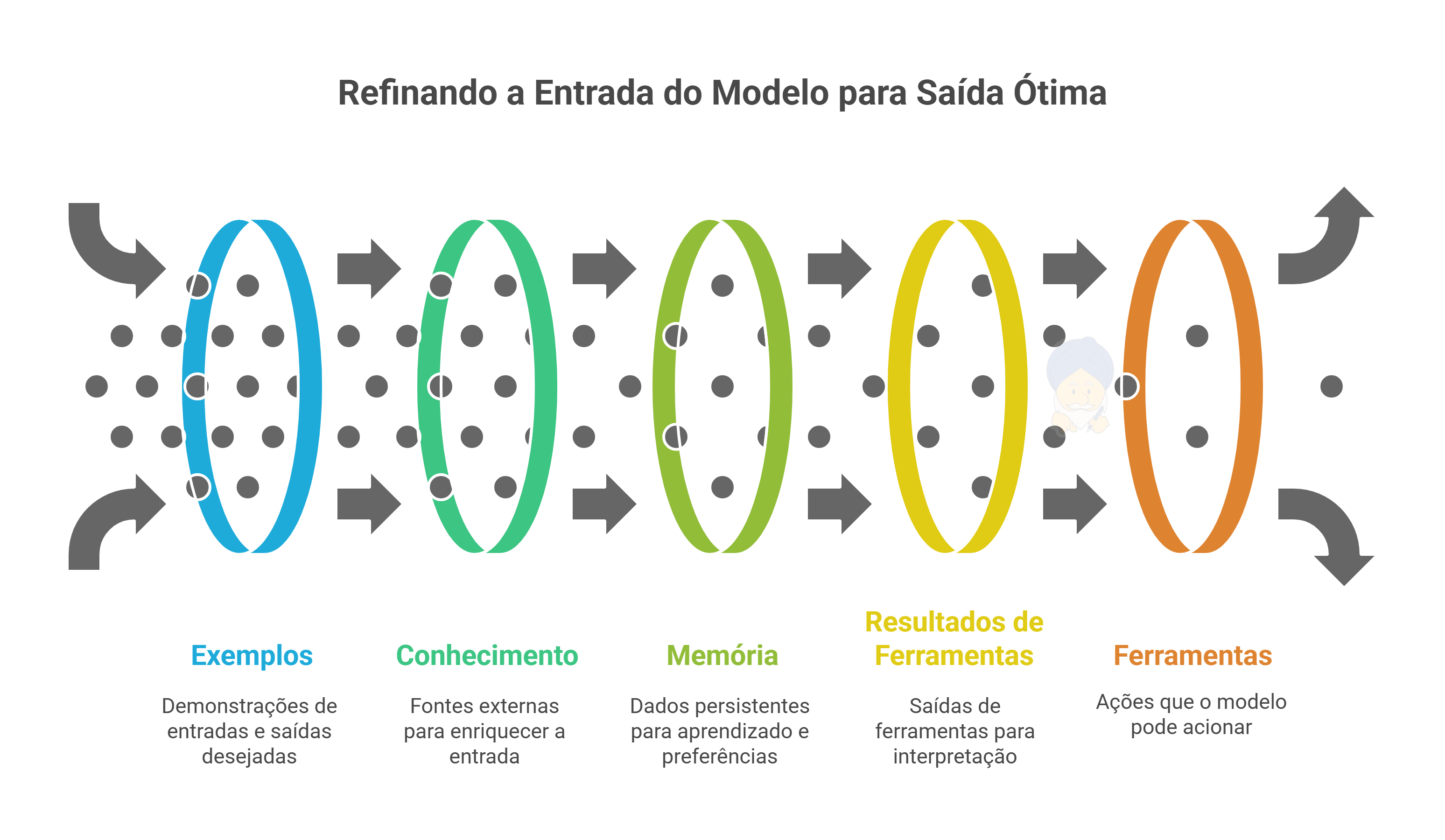
Instruções: O contrato de trabalho do modelo. Papel, objetivo, limites, formato de saída e critérios de qualidade. Escreva como requisito funcional, não como epifania criativa. Trave o tom, o público e o que é proibido. Toda instabilidade começa aqui.
Exemplos: Demonstração de entradas e saídas desejadas. Poucos, curtos e representativos. Exemplos errados ensinam o erro com eficiência. Mantenha um repositório versionado de “goldens” por tarefa.
Conhecimento: Fontes externas que você injeta a cada pergunta. É o território do RAG. Selecione passagens curtas e citáveis. Prefira chunks com metadados e score de relevância. Conhecimento sem procedência vira opinião.
Memória: O que persiste entre interações. Curta duração para estado da conversa. Longa duração para preferências e aprendizados. Memória sem política de esquecimento vira vazamento de privacidade. Memória sem chaves de segmentação vira confusão de identidade.
Resultados de ferramentas: Saídas de pesquisas, cálculos, bancos e serviços. Entregue ao modelo resultados limpos e autocontidos, com resumo e campos críticos. Faça o LLM interpretar o dado, não limpar sujeira.
Ferramentas: A lista de ações que o modelo pode acionar. Defina spec rigoroso, parâmetros tipados e mensagens de erro úteis. Sem limites claros, você cria um agente que chama tudo o tempo todo e explode latência e custo.
Orquestração é estratégia de produto
O erro mais comum é tratar prompt, RAG, memória e tools como features isoladas. Você precisa de um orquestrador que escolha, em tempo de execução, quais blocos ativar, em que ordem e com qual orçamento de tokens.
Pense em três alavancas de negócio.
Precisão: Mais fontes tendem a melhorar resposta até um ponto. Depois começa a diluir. Ajuste o limiar de relevância e o número de passagens. Avalie com conjuntos fixos de perguntas por tarefa, não “sensação de qualidade”.
Custo: Defina tetos de tokens por etapa. Use compressão de contexto, resumos hierárquicos e formatos estruturados. Faça cache de tudo que puder. Otimize para custo por resposta correta, não para custo por chamada.
Latência: Paralelize buscas e validações. Adie chamadas caras até ter alta confiança que serão necessárias. Implemente “respostas em duas fases” quando o usuário aceita uma prévia rápida seguida do resultado final.
Design de instruções que não quebram
Escreva instruções como especificação.
Papel e objetivo em duas linhas.
Entradas esperadas e suposições permitidas.
Critérios de qualidade com lista fechada.
Formato de saída validável por máquina.
Restrições explícitas do que não fazer.
Teste instruções com variações adversariais. Troque palavras, ordem, números e verifique se o comportamento se mantém. Prompts que dependem de frases mágicas não escalam.
Exemplos que ensinam, não confundem
Um bom conjunto de poucos exemplos vale mais do que 50 medianos. Cubra o caso feliz, um caso limite e um caso que deve falhar. Marque onde o modelo deve dizer “não sei”. Avalie exemplos continuamente com dados reais. Se o fluxo muda, seus exemplos mudam.
Conhecimento com procedência
RAG sem curadoria vira despejo de PDFs. Defina políticas.
Indexe somente fontes com dono, data e licença.
Chunk pequeno, bem rotulado e fácil de citar.
Rankeie por similaridade e por autoridade.
Faça pós-seleção com um verificador leve antes de ir para o LLM.
Inclua a procedência na resposta. Transparência reduz disputa com o usuário e ajuda seu time de suporte.
Memória com limites
Crie um “contrato de memória”.
O que lembrar.
Por quanto tempo.
Para qual escopo de usuário.
Como o usuário audita e apaga.
Implemente resumos periódicos para comprimir histórico longo. Promova apenas fatos estáveis para memória de longo prazo. Preferências são fortes candidatas. Desabafos de momento, não.
Ferramentas com especificação e simulador
Trate cada tool como uma API pública. Schemas, exemplos, mensagens de erro e limites. Construa um simulador de ferramentas para treinar e depurar sem tocar nos serviços reais. Quanto mais determinística a tool, menos o modelo precisa “adivinhar” parâmetros.
Resultados legíveis pelo modelo
O LLM interpreta melhor dados previsíveis. Entregue sempre um bloco curto de resumo humano seguido de JSON enxuto e validável. Nomes de campos precisam ser literais e estáveis. Unidades e intervalos devem acompanhar cada valor que possa gerar ambiguidade. Evite objetos aninhados profundos que forçam o modelo a navegar estrutura. Prefira listas de registros planos com chaves claras, ideais para comparação linha a linha.
Envelope recomendado
Use um envelope que o LLM reconhece em qualquer ferramenta. Primeiro um mini resumo em linguagem natural com 1 a 3 frases. Depois um objeto JSON com metadados, schema e payload. Assim você dá contexto sem gastar muitos tokens nem depender de interpretação livre.
Resumo: cálculo de LTV executado com janela de 12 meses. Entradas verificados e consistentes. Nenhuma anomalia.{
"meta": {
"task": "ltv_estimate",
"source": "billing_db.v2",
"generated_at": "2025-08-25T20:17:00Z",
"currency": "BRL",
"confidence": 0.92
},
"schema": {
"customer_id": "string",
"ltv": "number BRL [0, +inf)",
"cohort_month": "YYYY-MM",
"plan": "enum{Junior,Pleno,Senior}",
"churned": "boolean"
},
"data": [
{"customer_id": "U123", "ltv": 412.35, "cohort_month": "2025-01", "plan": "Senior", "churned": false},
{"customer_id": "U124", "ltv": 198.10, "cohort_month": "2025-02", "plan": "Pleno", "churned": true}
],
"limits": {
"rows_returned": 2,
"rows_total": 2,
"page": 1,
"page_size": 100
}
}Regras para nomes, unidades e intervalos
Padronize nomes em snake_case e evite sinônimos. Nunca entregue “valor”, “quantidade” ou “taxa” sem sufixo significativo. Acrescente unidade no schema e, quando útil, como sufixo no nome. Numéricos devem vir normalizados e com locale neutro. Decisões binárias são booleanos verdadeiros, não “sim” ou “não”.
{
"schema": {
"arpu_monthly_brl": "number BRL [0, 10000]",
"conversion_rate_pct": "number percent [0, 100]",
"latency_ms_p95": "integer ms [0, +inf)"
}
}Versão tidy para dados tabelares
Sempre que houver lista de itens comparáveis, forneça uma versão tidy. Cada linha é uma observação, cada coluna é uma variável, cada célula tem um valor. Isso permite que o LLM agregue, filtre e compare sem reestruturação.
{
"tidy": [
{"metric": "signup", "channel": "paid_search", "date": "2025-08-01", "value": 341},
{"metric": "signup", "channel": "organic", "date": "2025-08-01", "value": 589}
]
}
Campos calculados e rastreabilidade
Para números derivados, inclua fórmula simplificada e origens. Isso reduz alucinação de método e facilita auditoria.
{
"derived": {
"ltv_formula": "arpu_monthly_brl * gross_margin_pct/100 * avg_lifespan_months",
"inputs": ["arpu_monthly_brl", "gross_margin_pct", "avg_lifespan_months"]
}
}Valores ausentes, erros e anomalias
Ausência precisa ser explícita. Diferencie null, zero e “não aplicável”. Liste erros e alertas fora do payload para o modelo poder tratá-los sem confundir com dados válidos.
{
"warnings": [
{"code": "OUTLIER", "field": "ltv", "row": "U987", "detail": "value above p99"}
],
"errors": [
{"code": "MISSING_FIELD", "field": "cohort_month", "row": "U654"}
]
}
Datas, ID e paginação
Use ISO 8601 UTC para datas e horas. IDs devem ser opacos e estáveis. Inclua bloco de paginação com limites e total. O LLM decide quando pedir a próxima página sem adivinhar.
{
"limits": {
"rows_returned": 100,
"rows_total": 7843,
"page": 3,
"page_size": 100,
"next_page_token": "eyJwYWdlIjo0fQ"
}
}
Boas práticas para consumo pelo LLM
Comece sempre com o mini resumo humano. Traga números já agregados para o caso de uso, mais uma amostra tidy de linhas para referência. Evite múltiplas representações do mesmo valor. Se houver escolha entre média, mediana e p95, explicite o motivo no meta. Quando envolver dinheiro, inclua moeda e arredondamento. Para taxas, entregue percentuais como números de 0 a 100 com duas casas.
Validação automática antes de enviar ao modelo
Implemente checagens baratas que rodam no orquestrador.
Tipos e domínios conforme schema.
Intervalos válidos e monotonicidade quando aplicável.
Consistência entre campos dependentes.
Limite de linhas e tamanho estimado em tokens.
Redação de PII e mascaramento de IDs sensíveis.
Exemplo de validador declarativo:
{
"validators": [
{"field": "conversion_rate_pct", "rule": "between", "args": [0,100]},
{"fields": ["revenue_brl","orders_count"], "rule": "revenue>=orders_count*1.0"}
]
}
Formatos de resposta que o LLM devolve
Peça retorno em um dos três formatos e valide com regex ou JSON Schema. Primeiro, rascunho curto para pré-visualização. Segundo, resposta final com citações e números. Terceiro, bloco estruturado com decisões chave.
{
"expected_output": {
"summary_markdown": "string",
"citations": "array<url>",
"decisions": [
{"name": "next_action", "options": ["collect_more_data","ship_A","ship_B"]}
]
}
}
Redução de tokens com compressão semântica
Quando o payload estourar orçamento, aplique compressão antes do LLM principal. Gere um “digest” com estatísticas e outliers, mantendo amostra representativa. Inclua checksum do conjunto original para rastreabilidade.
{
"digest": {
"rows_sampled": 1000,
"checksum_sha256": "f7a1…",
"stats": {"mean_ltv_brl": 268.44, "p95_ltv_brl": 612.12, "outliers": 11}
}
}
Pitfalls comuns e como evitar
Misturar locale numérico quebra parsing. Campos polissêmicos induzem resposta errada. JSON aninhado profundo aumenta custo sem ganho. Textos longos junto do payload diluem atenção do modelo. Falta de unidade e data de coleta compromete comparação temporal. Corrija na fonte, não no prompt.
Métrica de qualidade de formato
Meça aderência ao schema, taxa de parse sem erro, tokens por payload útil e correlação entre mudanças de formato e acerto final. Otimize para custo por resposta correta mantendo p95 de latência sob meta definida. O formato é parte do produto, não do transporte.
Métricas que importam
Avalie por tarefa, não por modelo.
Accuracy operacional por caso de uso.
Adesão à instrução medida por validadores automáticos.
Citação de fonte quando aplicável.
Custo por resposta correta.
Latência p95 por rota.
Taxa de escalonamento para humano ou fallback.
Mantenha benchmarks estáveis e um conjunto “congelado” de perguntas de regressão. Qualquer mudança de prompt, índice ou ferramenta precisa passar por esse portão.
Segurança e governança de contexto
Contexto vaza. Implemente camadas de proteção.
Redação automática de dados sensíveis antes do RAG.
Listas de bloqueio e verificadores de saída para PII.
Controles de acesso por origem do conteúdo indexado.
Logs assinados das decisões do orquestrador.
Sem governança, você constrói dívida ética e regulatória além da dívida técnica.
Playbook de implementação em 30 dias
Semana 1: Mapeie tarefas críticas e defina para cada uma o contrato de instrução, duas ferramentas essenciais e um conjunto mínimo de exemplos e perguntas de avaliação.
Semana 2: Monte o pipeline de RAG com curadoria mínima, indexe só o necessário e já com metadados. Crie validadores automáticos para formato de saída e citação.
Semana 3: Implemente orquestrador simples. Ordem recomendada: instruções, exemplos, RAG leve, tools apenas quando o verificador indicar necessidade, memória no final para atualizar preferências.
Semana 4: Ative telemetria, rode experimentos de custo e latência, faça compressão de contexto, estabeleça política de memória e publique o primeiro relatório de qualidade por tarefa.
Erros frequentes que custam caro
Prompt gigante tentando resolver falta de dados.
Indexar a intranet inteira e chamar de RAG.
Memória sem consentimento e sem apagar.
Tools com descrições vagas que forçam o LLM a chutar parâmetros.
Métricas focadas em tokens por chamada em vez de custo por acerto.
Ausência de simuladores e de conjuntos de regressão.
O que muda para o papel de PM
Seu backlog agora tem itens como “reduzir alucinação em 30% neste fluxo”, “baixar latência p95 em 400ms via paralelização” e “aumentar taxa de citação de fonte para 90%”. A conversa deixa de ser “qual modelo” e vira “qual evidência, em qual ordem, com qual orçamento”. É produto, não mágica.
A corrida atual não é por modelos. É por contexto útil, barato e governado. Sua aplicação já tem tudo para performar melhor do que hoje. Falta decidir o que o modelo deve saber, quando e a que custo. A pergunta é direta. Você está orquestrando evidências ou despejando textos no prompt?
Conteúdos para aprofundar
OpenAI – Function Calling & Ferramentas
Guia oficial de function calling na API OpenAI:
OpenAI documentation – Function Calling AtamelDocumentação específica para uso com Assistants API:
OpenAI Assistants – Tools/Function Calling OpenAI Platform
Anthropic – Engenharia de Prompt e Ferramentas
Visão geral sobre engenharia de prompts (Prompt Engineering) na API Claude:
Anthropic documentation – Prompt Engineering OverviewGuia com melhores práticas específicas para o Claude 4:
Anthropic documentation – Claude 4 Prompt Engineering
Google – Grounding e RAG no Vertex AI
Introdução ao grounding (RAG) com Vertex AI:
Google Cloud – Grounding Overview (Vertex AI)Blog oficial sobre grounding + RAG com Vertex AI Agent Builder (Jun 2024):
Google Cloud Blog – RAG and Grounding on VertexPostagem técnica mais recente (Jan 2025) sobre Vertex AI RAG Engine:
Google Developers Blog – Vertex AI RAG Engine Blog dos Desenvolvedores
Microsoft – Avaliação e Considerações de LLMs em Produção
Framework completo de métricas para LLMs da Microsoft (Set‑27‑2023):
Microsoft Research – How to Evaluate LLMs: A Complete Metric FrameworkGuia de fluxo de avaliação de LLM no Azure AI Studio (Mai‑2024):
Microsoft Tech Community – Evaluation Flows for LLMs in Azure AI Studio
LlamaIndex – Pipelines de RAG
Documentação introdutória sobre RAG:
LlamaIndex – Introduction to RAGGuia com performance e otimizações para RAG:
LlamaIndex – Building Performant RAG Applications for ProductionExemplo prático “build RAG from scratch”:
LlamaIndex – Building RAG from Scratch (open‑source)
LangChain – Guia e Tutoriais de RAG
Tutorial para construir uma aplicação RAG em Python:
LangChain – Build a RAG App: Part 1 (Python)Guia conceitual de RAG:
LangChain Docs – Concepts – RAGTutoriais adicionais que abrangem fontes, histórico de chat, caching e parsing de JSON:
LangChain – Build RAG App: Part 2 (QA/chat history)
Ainda extremamente subestimado no Brasil. Obrigado pelas refs!